Introduction
For the past year, many startups have been running their engineering workflows through AI coding assistants — Cursor, Cline, Continue, Windsurf — that gave relatively cheap access to powerful models like Claude. The economics worked because these tools bundled model access into a flat subscription.
That model is cracking. Anthropic is restricting how third-party tools access their models, pushing everyone toward direct API usage with per-token billing. For a 10-person engineering team that's been leaning heavily on AI-assisted coding, this could mean going from $200/month in subscriptions to $800-2000/month in API costs.
This isn't a crisis. It's a forcing function to get smarter about how your team uses AI.
When AWS first became popular, startups threw everything on the biggest instances they could afford. Then the bills came. Smart companies learned to right-size: put the heavy compute where it matters, use spot instances for batch jobs, cache aggressively.
The same logic applies to AI model usage. Right now, most teams are using the equivalent of a c5.4xlarge for every task — sending complex reasoning models to write boilerplate code, format JSON, or generate test stubs.
Here's what forward-thinking startups are doing:
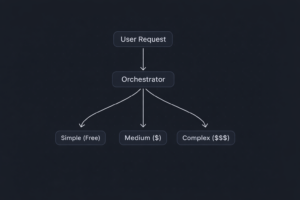
Tier 1 — Architecture and Planning (Claude Opus / GPT-4.5): Use the best model for high-stakes decisions: system design, complex debugging, security reviews, architecture planning. This is maybe 10-15% of your total AI requests but it's where quality matters most.
Tier 2 — Day-to-Day Coding (Claude Sonnet / GPT-4o): The workhorse tier. Feature implementation, code reviews, refactoring. Good enough for 90% of real coding work. This is 40-50% of requests.
Tier 3 — Routine Tasks (Claude Haiku / GPT-4o Mini / Local Models): Boilerplate generation, test writing, documentation, code formatting, simple completions. This is 40-50% of requests and it absolutely does not need an expensive model.

As businesses increasingly rely on digital technologies, the risk of cyber threats also grows. A robust IT service provider will implement cutting-edge cybersecurity measures to safeguard your valuable data, sensitive information, and intellectual property. From firewall protection to regular vulnerability assessments, a comprehensive security strategy ensures that your business stays protected against cyberattacks.
The Cost Math
Let's say your team generates 50 million tokens per month (not unusual for a 10-person team using AI heavily).
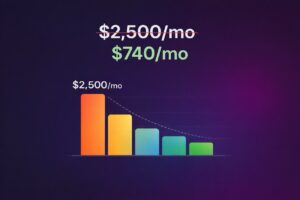
Old way (everything on Opus-class models): 50M tokens at blended rates ≈ $2,000-3,000/month.
Smart routing: 7.5M tokens on Tier 1 (Opus): ~$450. 22.5M tokens on Tier 2 (Sonnet): ~$270. 20M tokens on Tier 3 (Haiku/Mini): ~$20. Total: ~$740/month.
That's a 60-75% reduction. For a startup burning cash, that matters.
Implementation: Don't Build, Integrate
You don't need to build a complex orchestration system from scratch. Here are practical approaches:
LiteLLM — An open-source proxy that sits in front of multiple model APIs. Configure routing rules, set budgets per team member, and swap models without changing your code.
Custom middleware — A thin API layer that classifies incoming requests and routes them. This can be 200 lines of Python and save you thousands per month.
Team-level policies — Sometimes the simplest solution works. Give your team guidelines: use Opus for architecture discussions and complex debugging, use Sonnet for daily coding, use Haiku for tests and docs.
The Competitive Angle
Here's what most founders miss: this shift creates an advantage for teams that adapt quickly. If your competitor is still throwing Opus at every autocomplete while you're running an efficient multi-model setup, you're spending 70% less on AI while getting comparable output. That's runway. That's hiring another engineer.
The startups that will win the AI-assisted development game aren't the ones using the most expensive models — they're the ones using the right model for each task.
What to Do This Week
1. Audit your AI spend. How many tokens is your team actually using? Which models? Most tools have usage dashboards — go look at them.
2. Classify your usage. What percentage is complex reasoning vs. routine coding vs. boilerplate? You'll probably find 60%+ is routine.
3. Set up a proxy. Deploy LiteLLM or a simple routing layer. Start directing routine tasks to cheaper models.
4. Set budgets. Give each team member a monthly API budget. People get creative about efficiency when there's a limit.
5. Measure quality. Track whether the cheaper models actually hurt output quality. For most routine tasks, they won't.
Key Takeaways:
- Anthropic's API billing shift could 3-5x your AI costs if you don't adapt
- Most AI coding tasks (60%+) don't need the most expensive model
- A tiered model strategy can cut costs by 60-75% with minimal quality loss
- Tools like LiteLLM make multi-model routing easy to implement
- Early optimization creates a compounding cost advantage over competitors
Audit your team's AI usage this week. Pull the numbers, classify the tasks, and estimate what a tiered approach would save you. Then set up a 2-week pilot with a routing proxy. The savings will speak for themselves.
Frequently Asked Questions
How much will Anthropic's API changes increase my startup's AI costs?
For a 10-person engineering team that heavily uses AI-assisted coding, costs could jump from $200/month in flat subscriptions to $800-2,000/month in direct API billing. The exact increase depends on your team's token volume and which models you use.
What is LiteLLM and how does it help reduce AI costs?
LiteLLM is an open-source proxy that sits in front of multiple AI model APIs (Anthropic, OpenAI, etc.). It lets you configure routing rules to send simple tasks to cheap models and complex tasks to expensive ones, set per-team-member budgets, and swap models without changing your application code.
What is the best tiered model strategy for a startup engineering team?
The optimal three-tier strategy is: Tier 1 (10-15% of requests) — Claude Opus or GPT-4.5 for architecture and planning. Tier 2 (40-50%) — Claude Sonnet or GPT-4o for day-to-day coding. Tier 3 (40-50%) — Claude Haiku, GPT-4o Mini, or local models for routine tasks. This cuts costs by 60-75%.
How do I audit my startup's AI spending?
Start by listing every AI tool subscription your team pays for (Cursor, ChatGPT Plus, Copilot, etc.). Then track actual usage for one week — classify prompts as complex, medium, or simple. Check token usage dashboards in each tool. Most teams discover 60%+ of their usage is routine tasks that don't need expensive models.
Can multi-model routing hurt code quality for my team?
For routine tasks like boilerplate generation, test writing, and code formatting (40-50% of typical usage), cheaper models produce comparable quality. For complex architecture and debugging (10-15%), you still use premium models. The net impact on code quality is minimal, but you should track metrics during a 2-week pilot to confirm.
How does AI cost optimization give startups a competitive advantage?
If your competitor spends $3,000/month on AI while you spend $740/month for comparable output, you save $27,000 annually. That's enough to hire another engineer or extend your runway. Early optimization creates a compounding advantage as AI usage grows with team size.
![]()