Introduction
Anthropic has been tightening the screws on how third-party tools access Claude. The company is pushing hard toward direct API billing — meaning if you want Claude's best models, you're going to pay per token through their API, not ride on a flat subscription through someone else's tool.
This isn't surprising. Anthropic burns enormous compute costs, and letting tools like Cursor funnel unlimited requests through subsidized access was never going to last. The shift is simple: use our API, pay per token, and we'll give you the best models. Use someone else's wrapper, and expect rate limits, degraded model access, or outright blocks.
For developers who leaned on Claude as the backbone of their AI-assisted coding, this changes the math. But it also opens up something more interesting: the multi-model orchestration pattern.
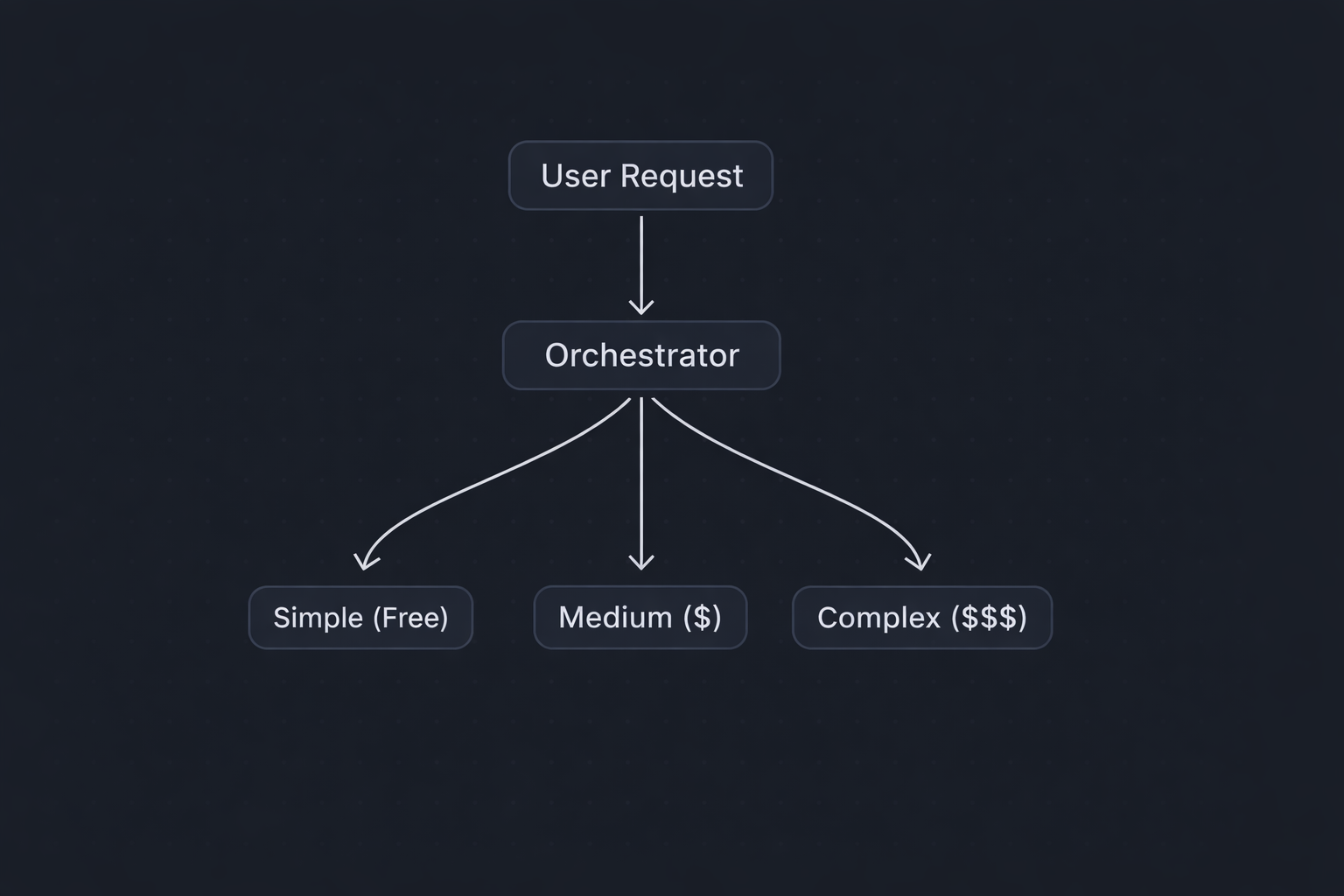
Here's the core idea. Instead of sending every task to one expensive model, you split your workflow into two roles:
Orchestrator: The "brain" that plans, reasons, and makes decisions. This is where you want your smartest model — Claude Opus, for example.
Executor: The "hands" that carry out well-defined tasks. This is where cheaper models shine — GPT-4o Mini, Claude Haiku, Llama 3 running locally, or Mistral.
The orchestrator looks at your problem, breaks it into steps, and decides which executor should handle each step. Think of it like a senior engineer who delegates to junior devs — you don't need a principal engineer writing boilerplate.
Here's a practical setup you can build today:
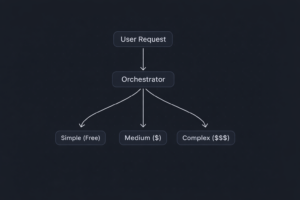
Step 1: User sends a complex coding request.
Step 2: Claude Opus (orchestrator) analyzes the request — breaks it into subtasks, classifies each subtask by complexity, assigns each to the appropriate model.
Step 3: Simple tasks go to GPT-4o Mini or local Llama 3 (~$0.15/M tokens). Medium tasks go to Claude Sonnet or GPT-4o (~$3/M tokens). Complex reasoning stays with Claude Opus (~$15/M tokens).
Step 4: Orchestrator reviews outputs, stitches them together.
Step 5: Final result returned to user.
You can wire this up with a simple Python script using the Anthropic and OpenAI SDKs. A simplified router classifies tasks as SIMPLE, MEDIUM, or COMPLEX and routes to the appropriate model — cheap local models for simple work, Sonnet for medium tasks, and Opus for complex reasoning. In production, you'd add caching, retry logic, and a more sophisticated routing layer.

As businesses increasingly rely on digital technologies, the risk of cyber threats also grows. A robust IT service provider will implement cutting-edge cybersecurity measures to safeguard your valuable data, sensitive information, and intellectual property. From firewall protection to regular vulnerability assessments, a comprehensive security strategy ensures that your business stays protected against cyberattacks.
The Hybrid Cloud and Local Setup
Here's where it gets really interesting. You don't have to send everything to an API. For many executor tasks — generating boilerplate, formatting code, writing tests for well-defined functions — a local model running on Ollama or LM Studio works just fine.
A practical hybrid setup: Cloud (orchestrator) — Claude Opus via API handles planning, architecture decisions, complex debugging. Cloud (executor) — GPT-4o Mini or Claude Haiku handles medium-complexity tasks when local models fall short. Local (executor) — Llama 3 8B or Mistral 7B via Ollama handles simple code generation, boilerplate, formatting.
Your monthly cost drops from potentially hundreds of dollars to maybe $20-40, depending on volume.
Why This Is Actually Better
The old model — throwing everything at one "best" model — was wasteful. You were paying premium prices for Claude Opus to write import statements and boilerplate. The orchestrator pattern isn't just cheaper; it's architecturally sound.
It also makes you resilient. If Anthropic has an outage, your simple tasks still run locally. If OpenAI changes pricing, you swap executors. You're not locked into any single provider.
Getting Started
1. Set up API accounts with Anthropic and OpenAI (budget $20 each to start).
2. Install Ollama locally and pull Llama 3 8B.
3. Build a simple router script.
4. Start logging which tasks go where and how much each costs.
5. Iterate — adjust your routing logic based on real data.
Key Takeaways:
- Anthropic is pushing toward API-first billing, making unlimited third-party access a thing of the past
- The orchestrator/executor pattern lets you use expensive models only when you need them
- Claude Opus works best as a "brain" that delegates to cheaper models for routine work
- Hybrid cloud + local setups can cut costs by 60-80% without sacrificing quality
- Building model-agnostic workflows protects you from future pricing or access changes
Start building your orchestration layer this weekend. Set up a simple router with one smart model and one cheap model. Track your costs for a week. You'll be surprised how little you actually need the expensive model.
Frequently Asked Questions
What is multi-model AI orchestration?
Multi-model AI orchestration is a pattern where you use multiple AI models together instead of relying on a single one. A smart 'orchestrator' model (like Claude Opus) plans and delegates tasks, while cheaper 'executor' models (like GPT-4o Mini, Claude Haiku, or local Llama 3) handle the actual work. This approach cuts costs by 60-80% while maintaining quality.
Why is Anthropic restricting third-party access to Claude?
Anthropic is shifting to direct API billing because subsidizing unlimited access through third-party tools like Cursor was financially unsustainable. They burn enormous compute costs, and the flat subscription model used by third-party tools didn't cover the actual cost of inference. The shift pushes users toward per-token billing through their own API.
How much does a multi-model AI setup cost per month?
A well-configured multi-model setup typically costs $20-40 per month, compared to $100+ with single-model approaches. By routing 50% of tasks to free local models, 35% to cheap cloud models like Claude Haiku ($0.25/M tokens), and only 15% to premium models like Claude Opus ($15/M tokens), you save 60-80%.
What is the best local AI model for coding in 2025?
Llama 3 8B running on Ollama is currently the best local model for coding tasks. It handles autocomplete, boilerplate generation, test writing, and simple code questions at roughly 70-80% the quality of cloud models — completely free with no API costs or rate limits.
How do I build an AI task router in Python?
You can build a basic AI task router using the Anthropic and OpenAI Python SDKs. The router classifies incoming tasks by complexity (simple, medium, complex) using heuristics like token count and keyword detection, then routes simple tasks to local models, medium tasks to Claude Haiku or GPT-4o Mini, and complex tasks to Claude Opus.
Can I use Claude Opus and GPT-4o together in the same workflow?
Yes, and this is actually the recommended approach. Claude Opus excels at planning, reasoning, and architecture decisions, while GPT-4o Mini handles routine coding tasks cheaply. Using them together through an orchestrator pattern gives you the best of both providers while reducing vendor lock-in.
![]()